SimpliVity’s Approach to Deduplication

There are two industry standards when it comes to duplication. The first type is Inline which occurs as data is being written. Second is Post-Process where data is analyzed after being written. So what’s the difference to using one over the other?
Note: While I recognize there are 5 billion things to keep in mind when it comes to Inline and Post-Process deduplication these are the ones that stood out to me.
With Inline new blocks are only created if the data does not exist. If the data is there, new meta data will reference the existing block. Few things to keep in mind with Inline are:

- A hash calculation is created in memory and stored on a storage device as data is written. This calculation has the potential of slowing down the process as data is being validated and indexed (latency).
- Since blocks of data are created as needed, less storage is required.
- There is CPU tax, unless you offload the process to dedicated hardware.
- Less IOPS are being sent to disk.
Post-Process removes duplicate data after it has been written to storage. There is a potential of having duplicate data until after the process validates. Few things to keep in mind with Post-Process are:

- No hash calculation needed up front on storage device, allowing the initial write process to take less time (in theory).
- Requires more storage since all data is written up front.
- There is a CPU and Disk tax during the Post-Process operation more latency is introduced.
- Less IOPS for applications (rereading blocks that have already been written).
During Virtualization Field Day 4 we got to see how Simplivity handles deduplication, here are my notes.
Disclaimer: I was a delegate at Virtualization Field Day 4. Gestalt IT paid my travel, lodging, and meals. I don’t receive any compensation nor am I required to write anything related to the event.
SimpliVity has a solution to solve the issues that plague using Inline and Post-Process deduplication. The secret sauce comes from using the virtual controller (brains) coupled with software and the OmniStack Accelerator card (muscle). By the way this is all done on their own proprietary operating system (SVT). Few things to keep in mind with SimpliVity:
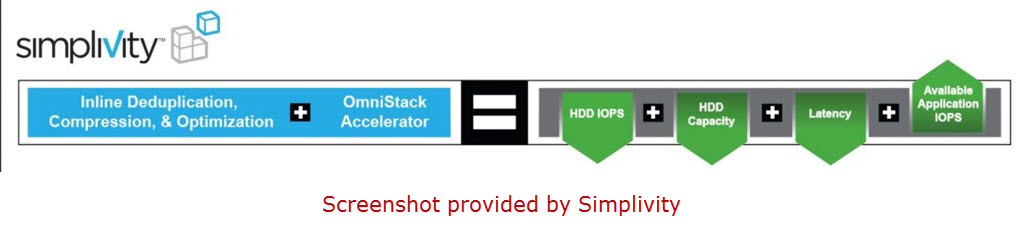
- Less IOPS going to hard drives (typical w/ Inline).
- Lower CPU & memory utilization.
- Lower latency on hard drive(s) doing less which allows more optimize IO.
- Less IOPS are being sent to disk more are available for applications.
As you can see from this simplistic (no pun intended) overview, SimpliVity provides deduplication in ways others don’t. The benefits include having the hash calculation take place on the OminStack Accelerator card instead of in memory. Meta data is separated out from data and held in pool of SSD, faster for reads. This eliminates the CPU and Disk tax as well as guaranteed IOPS for applications. This is just what they are doing with deduplication, compression gains the same benefits from the OminStack Accelerator card as well.